
Эволюция алгоритмов поисковых систем движется от оценки самого факта наличия документов и ссылок к оценке их качества путём анализа масштабных данных, собранных на основе пользовательского поведения. Нагляднее всего это видно в оппозиции PageRank - BrowseRank. Какие математические модели были предложены для оценки качества сайтов на основе того или иного фактора ранжирования? Какова история создания алгоритмов их вычисления? Несмотря на то, что применяемые поисковыми системами алгоритмы на сегодняшний день активно оперируют десятками и даже сотнями параметров, а методы обработки этих параметров держатся в секрете, тем не менее, необходимость практического применения определённых методик ставит вопрос о поиске и более детальном изучении данных об этих алгоритмах.
PR, ТиЦ и ссылочное ражнирование
1996 год, Стэнфордский университет - аспиранты Сергей Брин и Ларри Пейдж стартуют BackRub, исследовательский проект-поисковую систему с алгоритмом ранжирования, который был впервые обнародован по именем PageRank в начале 1998 года.
4 сентября 1998 года - зарегистрирована компания Google.

Ссылочыный граф. Только позже различными инструментами будут создаваться социальны графы, построенные на особенностях распределения информации, интересов и другой информации о пользователе. Начинается всё со ссылочного графа, который можно было построить на основе имевшегося на тот момент объема данных и методов его обработки.
Поисковик Яндекса, чей запуск был анонсирован между этими двумя событиями, в 1997 году, будет опираться на аналогичный механизм, который получит название ТиЦ или тематический индекс цитирования.
На момент появления, подход к вопросу обработки данных, доступных в Интернете, основанный на определёной "важности" страниц являлся передовым для поиска по интернету - необходимость сбора, обработки и систематизации BigData ставили перед создателями задачу применения соответствующих моделей для вычисления "веса" тех или иных страниц. Задача была решена при помощи дискретной математики (теория графов), с использованием приципов цепи Маркова с дискретным временем, и применением логарифмической шкалы для оценки веса страниц.
Иными словами, предлагалась модель ссылочного графа, где узлами были веб-документы, а рёбрами - ссылки. Так, говоря простым языком, родился всем известный принцип PR или ТиЦ, который широко применяется в SEO: чем больше ссылок с так называемых "трастовых" сайтов идёт на продвигаемый ресурс, тем выше соответствующий показатель ранжирования.
Однако как изящно ни была решена поставленная задача, очень скоро стало понятно, что этот алгоритм стало слишком легко "заспаммить" путём массовой скупки ссылок. Как результат, поисковики начали поиск новых путей решения возникшей проблемы.
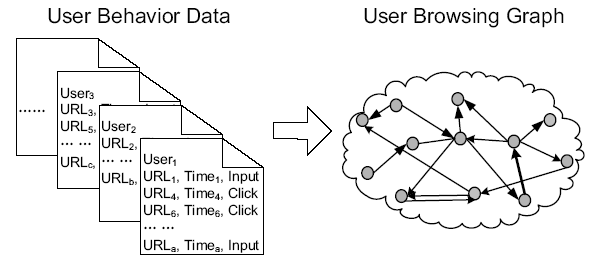
В отличие от PageRank, BrowseRank оперирует данными о времени, проведённом пользователями на сайте, что раскрывает релевантность ресурса. В свою очередь это также граф, но в отличие от ссылок, его рёбрами являются непосредственно переходы по ссылкам.
Browserank и поведенческие факторы
О поведенческих факторах как возможной альтернативе ссылочному ранжированию открыто заговорили в 2013 году. Однако конечно понятно, что данные о пользователях начали собираться гораздо раньше, просто к этому моменту у поисковых систем оказалось в руках огромное количество новых статистических данных о поведении пользователей.
Данные собираются через:
1. Надстройки для браузеров (например, Alexa)
2. Метрику (Яндекс.Метрика, Google Analytics и другие)
3. Специализированные браузеры (Chrome, Яндекс.Браузер)
Казалось бы, нет ничего проще: пусть пользователи сами, своими посещениями и поведением на сайте дадут поисковой системе знать, какой сайт отвечает запросу и предоставляет качественный релевантный материал. Однако это изящное решение могло основываться только на определённых данных: на то, чтобы собрать их, требовалось время.
Тем не менее, ещё в 2008 году Майкрософт аннонсирует новый алгоритм: BrowseRank - очередная разработка, в том же году представленная на SIGIR, знаменитой конференции, ежегодно устраиваемой одним из подразделений Ассоциации Вычислительной Техники, старейшей и наиболее крупной организацией в области вычислительной техники.
Позднее, с похожими материалами на SIGIR начнут презжать докладчики из Яндекса. В Дублине в 2013 году будет обнародован новый взгляд на BrowseRank: документ так и будет называться Fresh BrowseRank. В 2014 году представленная на SIGIR работа снова будет затрагивать тему поведенческих факторов.
Казавшаяся многим абсурдной идея отмены ссылочного ранжирования буквально витала в воздухе и само это событие произошло вполне закономерно. Равно как и закономерным было появление обновления алгоритма Hummingbird у Google.
Browserank снова строится на математической модели и снова в ход идёт теория графов. С той лишь разницей, что плечом графа становится переход по ссылке, а не сама ссылка. Также, в силу своей природы, Browserank может учитывать время, проведённое пользователем на странице.
Итак, если до недавнего времени алгоритмы поисковых систем требовали от сайтов наличие ссылок, то сейчас на первый план выходит не само наличие ссылочной массы, а движение пользователей по ссылкам и внимание, уделённое сайту.
Ещё в 2008 году критики метода высказывали точку зрения, что механизм не будет работать, так как уязвим для роботизированных накруток. На сегодняшний момент есть достоверные данные, подтверждающие, что ни одна роботизированная система не может полностью воспроизвести поведение человека равно так же, как ещё ни одна машина так и не смогла полноецнно пройти тест Тьюринга. Кроме того, современные системы - которые предположительно и должны стоять на вооружении таких гигантов, как Google и Яндекс - с лёгкостью вычисляют искусственную активность, не являющуюся живыми переходами пользователя - и имеет возможность баннить сайты, воспользовавшиеся подобной схемой без предупреждения и на неопределённый срок.
